
Summer Sale Limited Time 75% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = simple75
Pass the Databricks Certification Databricks-Certified-Data-Engineer-Associate Questions and answers with Dumpstech
Which of the following describes the type of workloads that are always compatible with Auto Loader?
Which of the following benefits is provided by the array functions from Spark SQL?
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
A data engineer has developed a data pipeline to ingest data from a JSON source using Auto Loader, but the engineer has not provided any type inference or schema hints in their pipeline. Upon reviewing the data, the data engineer has noticed that all of the columns in the target table are of the string type despite some of the fields only including float or boolean values.
Which of the following describes why Auto Loader inferred all of the columns to be of the string type?
A data engineer wants to schedule their Databricks SQL dashboard to refresh once per day, but they only want the associated SQL endpoint to be running when it is necessary.
Which of the following approaches can the data engineer use to minimize the total running time of the SQL endpoint used in the refresh schedule of their dashboard?
In which of the following scenarios should a data engineer use the MERGE INTO command instead of the INSERT INTO command?
A data engineer is working on a Databricks project that utilizes cloud storage. The data engineer wants to load several json files from containers on a storage account as soon as the file arrives within the storage account.
Which syntax should the data engineer follow to first load the files into a dataframe and check that it is working as expected using Python?
A data engineer needs to parse only png files in a directory that contains files with different suffixes. Which code should the data engineer use to achieve this task?
A)
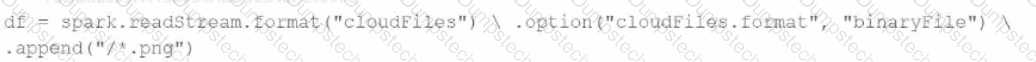
B)

C)
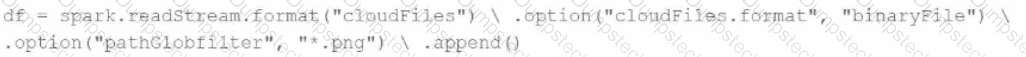
D)

A data engineer has written a function in a Databricks Notebook to calculate the population of bacteria in a given medium.

Analysts use this function in the notebook and sometimes provide input arguments of the wrong data type, which can cause errors during execution.
Which Databricks feature will help the data engineer quickly identify if an incorrect data type has been provided as input?
A data engineering project involves processing large batches of data on a daily schedule using ETL. The jobs are resource-intensive and vary in size, requiring a scalable, cost-efficient compute solution that can automatically scale based on the workload.
Which compute approach will satisfy the needs described?