Summer Sale Limited Time 75% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = simple75
Pass the Amazon Web Services AWS Certified Associate MLA-C01 Questions and answers with Dumpstech
A government agency is conducting a national census to assess program needs by area and city. The census form collects approximately 500 responses from each citizen. The agency needs to analyze the data to extract meaningful insights. The agency wants to reduce the dimensions of the high-dimensional data to uncover hidden patterns.
Which solution will meet these requirements?
An ML engineer needs to deploy ML models to get inferences from large datasets in an asynchronous manner. The ML engineer also needs to implement scheduled monitoring of the data quality of the models. The ML engineer must receive alerts when changes in data quality occur.
Which solution will meet these requirements?
An ML engineer needs to deploy ML models to get inferences from large datasets in an asynchronous manner. The ML engineer also needs to implement scheduled monitoring of the data quality of the models. The ML engineer must receive alerts when changes in data quality occur.
Which solution will meet these requirements?
An ML engineer is analyzing potential biases in a customer dataset before training an ML model. The dataset contains customer age (numeric), product reviews (text), and purchase outcomes (categorical).
Which statistical metrics should the ML engineer use to identify potential biases in the dataset before model training?
A credit card company has a fraud detection model in production on an Amazon SageMaker endpoint. The company develops a new version of the model. The company needs to assess the new model ' s performance by using live data and without affecting production end users.
Which solution will meet these requirements?
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records every second.
The company needs to implement a scalable solution on AWS to identify anomalous data points.
Which solution will meet these requirements with the LEAST operational overhead?
An ML engineer needs to organize a large set of text documents into topics. The ML engineer will not know what the topics are in advance. The ML engineer wants to use built-in algorithms or pre-trained models available through Amazon SageMaker AI to process the documents.
Which solution will meet these requirements?
A company has trained an ML model that is packaged in a container. The company will integrate the model with an existing Python web application. The company needs to host the model on AWS by using Kubernetes.
The company does not want to manage the control plane and must provision the resources in a repeatable manner. The infrastructure must be provisioned by using Python.
Which solution will meet these requirements?
A company has AWS Glue data processing jobs that are orchestrated by an AWS Glue workflow. The AWS Glue jobs can run on a schedule or can be launched manually.
The company is developing pipelines in Amazon SageMaker Pipelines for ML model development. The pipelines will use the output of the AWS Glue jobs during the data processing phase of model development. An ML engineer needs to implement a solution that integrates the AWS Glue jobs with the pipelines.
Which solution will meet these requirements with the LEAST operational overhead?
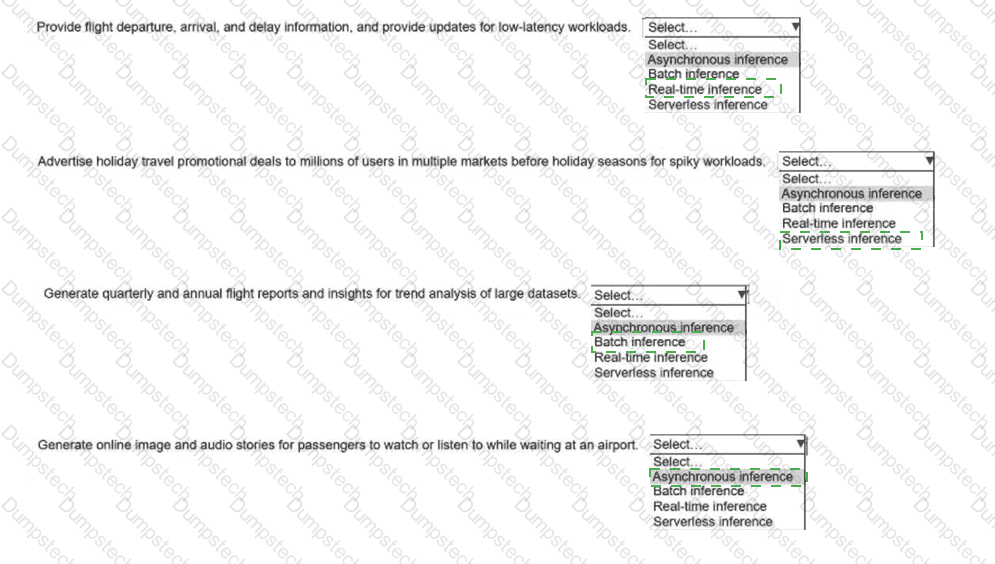
An airline company deploys ML models to one dozen Amazon SageMaker Al inference endpoints. The inference endpoints must be able to handle different types of
workloads in a cost-effective way.
Select the correct inference option from the following list to handle each type of workload. Select each inference option one time. (Select FOUR.)
Asynchronous inference
Batch inference
Real-time inference
Serverless inference