
Summer Sale Limited Time 75% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = simple75
Pass the Amazon Web Services AWS Certified Associate MLA-C01 Questions and answers with Dumpstech
A company has implemented a data ingestion pipeline for sales transactions from its ecommerce website. The company uses Amazon Data Firehose to ingest data into Amazon OpenSearch Service. The buffer interval of the Firehose stream is set for 60 seconds. An OpenSearch linear model generates real-time sales forecasts based on the data and presents the data in an OpenSearch dashboard.
The company needs to optimize the data ingestion pipeline to support sub-second latency for the real-time dashboard.
Which change to the architecture will meet these requirements?
A company uses an ML model to recommend videos to users. The model is deployed on Amazon SageMaker AI. The model performed well initially after deployment, but the model's performance has degraded over time.
Which solution can the company use to identify model drift in the future?
A company is creating an application that will recommend products for customers to purchase. The application will make API calls to Amazon Q Business. The company must ensure that responses from Amazon Q Business do not include the name of the company's main competitor.
Which solution will meet this requirement?
An ML engineer wants to deploy an Amazon SageMaker AI model for inference. The payload sizes are less than 3 MB. Processing time does not exceed 45 seconds. The traffic patterns will be irregular or unpredictable.
Which inference option will meet these requirements MOST cost-effectively?
A company is using an Amazon Redshift database as its single data source. Some of the data is sensitive.
A data scientist needs to use some of the sensitive data from the database. An ML engineer must give the data scientist access to the data without transforming the source data and without storing anonymized data in the database.
Which solution will meet these requirements with the LEAST implementation effort?
A financial company receives a high volume of real-time market data streams from an external provider. The streams consist of thousands of JSON records per second.
The company needs a scalable AWS solution to identify anomalous data points with the LEAST operational overhead.
Which solution will meet these requirements?
An ML engineer is using Amazon SageMaker Canvas to build a custom ML model from an imported dataset. The model must make continuous numeric predictions based on 10 years of data.
Which metric should the ML engineer use to evaluate the model’s performance?
An ML engineer needs to use an ML model to predict the price of apartments in a specific location.
Which metric should the ML engineer use to evaluate the model's performance?
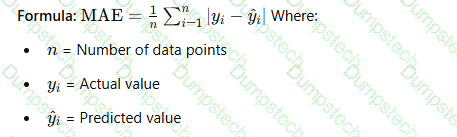
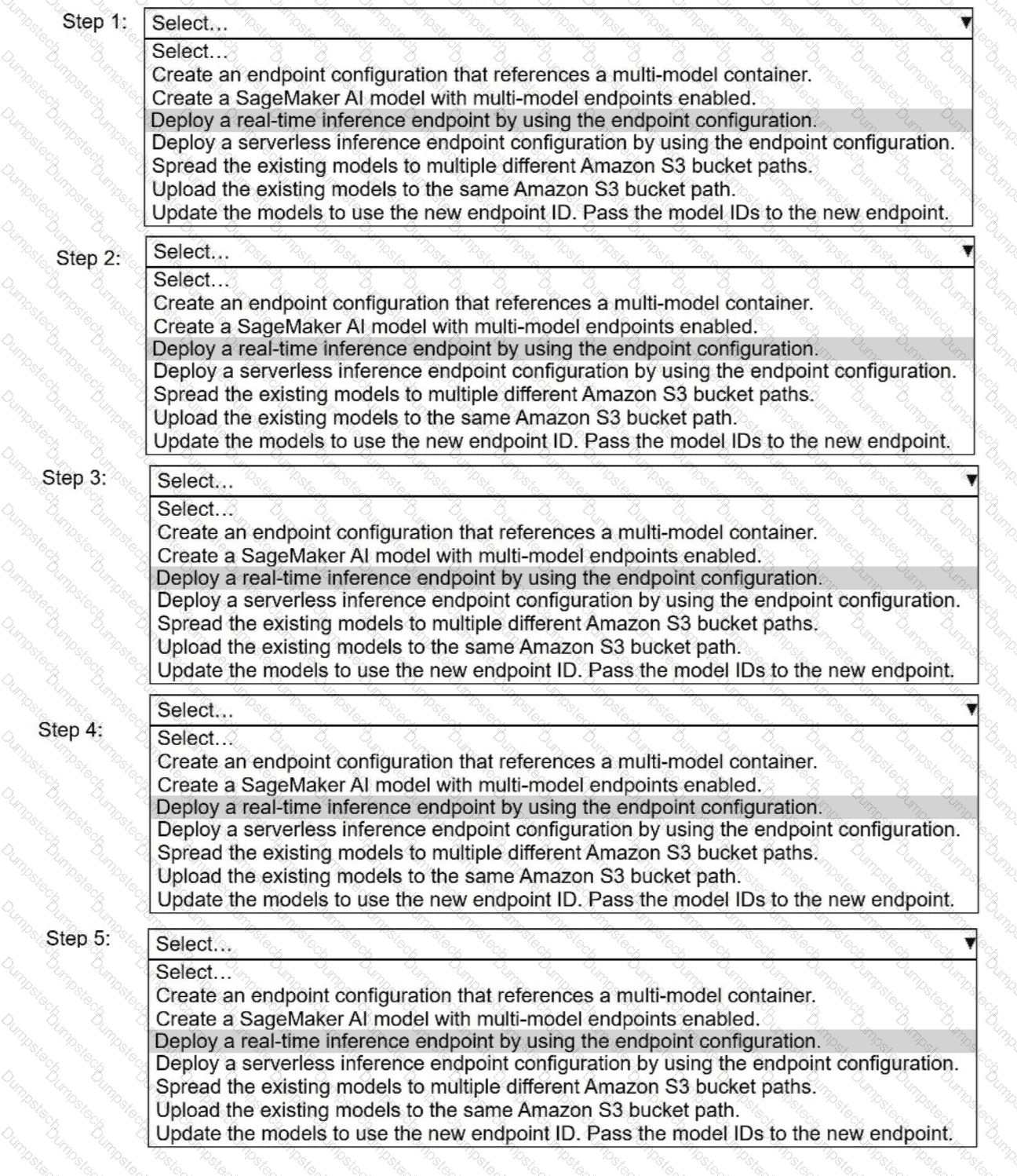
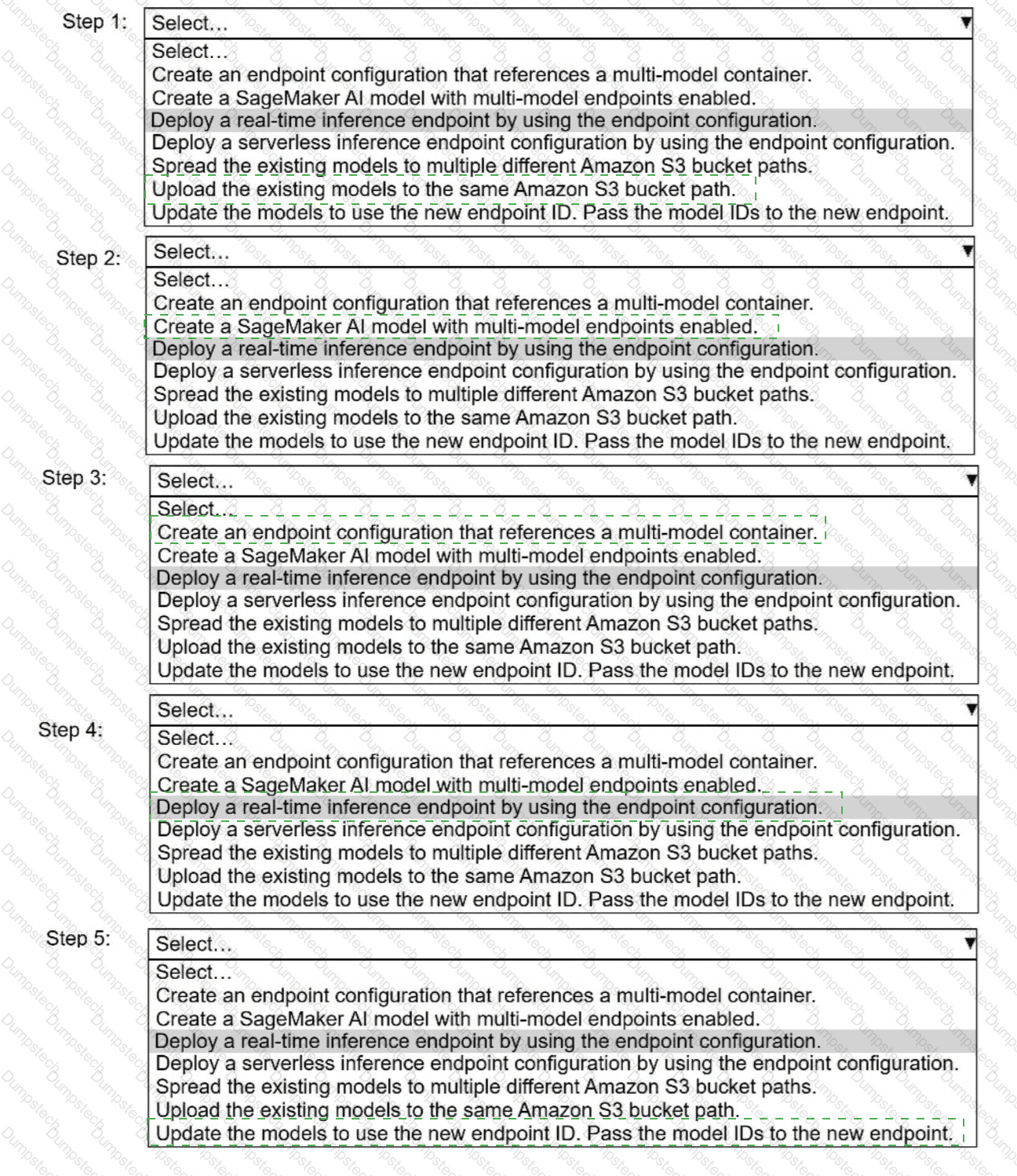
A company has built more than 50 models and deployed the models on Amazon SageMaker Al as real-time inference
endpoints. The company needs to reduce the costs of the SageMaker Al inference endpoints. The company used the same
ML framework to build the models. The company's customers require low-latency access to the models.
Select and order the correct steps from the following list to reduce the cost of inference and keep latency low. Select each
step one time or not at all. (Select and order FIVE.)
· Create an endpoint configuration that references a multi-model container.
. Create a SageMaker Al model with multi-model endpoints enabled.
. Deploy a real-time inference endpoint by using the endpoint configuration.
. Deploy a serverless inference endpoint configuration by using the endpoint configuration.
· Spread the existing models to multiple different Amazon S3 bucket paths.
. Upload the existing models to the same Amazon S3 bucket path.
. Update the models to use the new endpoint ID. Pass the model IDs to the new endpoint.
An ML engineer needs to deploy ML models to get inferences from large datasets in an asynchronous manner. The ML engineer also needs to implement scheduled monitoring of the data quality of the models. The ML engineer must receive alerts when changes in data quality occur.
Which solution will meet these requirements?