
Summer Sale Limited Time 75% Discount Offer - Ends in 0d 00h 00m 00s - Coupon code = simple75
Pass the Microsoft Certified: Azure Databricks Data Engineer DP-750 Questions and answers with Dumpstech
Exam DP-750 Premium Access
View all detail and faqs for the DP-750 exam
You have an Azure Databticks workspace that contains an all-purpose compute cluster named Cluster1. Cluser1 is used for
interactive development.
You need to configure Cluster1 to meet the following requirements:
• Automatically add and remove worker nodes based on workload demand
• Automatically shut down when the cluster has been idle for a specific period.
What should you configure for each requirement? To answer, drag the appropriate options to the correct requirements. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.


You have an Azure Databricks workspace named Workspace1. You create a compute cluster named Cluser1 that will be used to ingest data.
You need to install the required libraries on Cluster 1. The solution must use Unity Catalog for access control. What should you do?
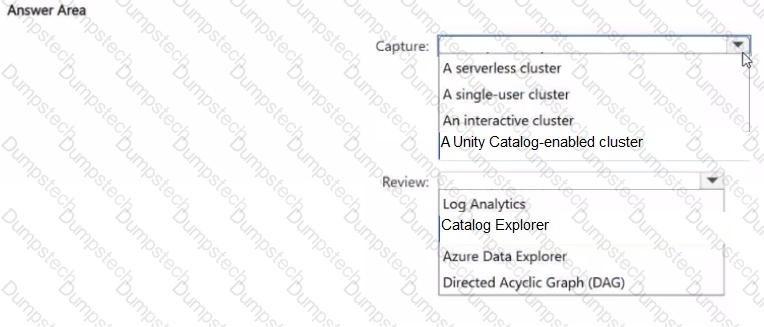
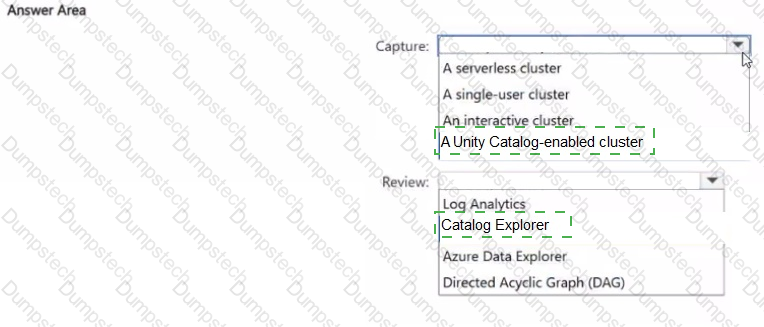
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to ensure that data lineage is captured and can be reviewed for tables accessed by Databricks notebooks and jobs. The solution must minimize administrative effort.
Which compute configuration should you use to capture the data lineage, and what should you use to review the data lineage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You have a Lakeflow Spark Declarative Pipelines (SDP) pipeline that writes numerical data to a table named Table1 by using a data quality validation rule named rule1.
You need to modify rule1 to meet the following requirements:
Ensure that amount is always greater than 0.
Prevent an update to Table1 from being committed when data that violates rule1 is detected.
Which statement should you execute?
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a managed Delta table named Sales. Sales stores transaction data and contains the following columns:
• transactionjd (string)
• transaction date (date)
• amount (decimal)
You need to implement the following data quality requirements by using table-level data quality enforcement:
• amount must be greater than 0.
• transaction id must never be null.
• Invalid records must be rejected when data is written to the Sales table.
What should you do?
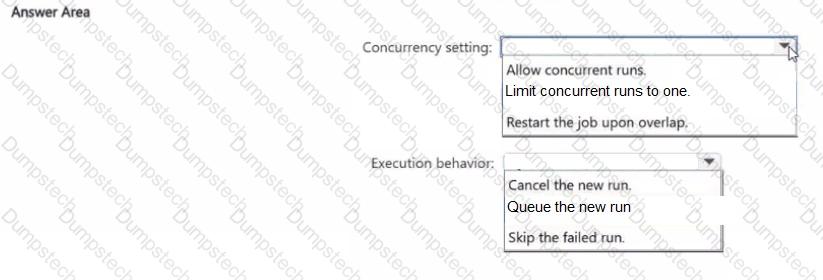
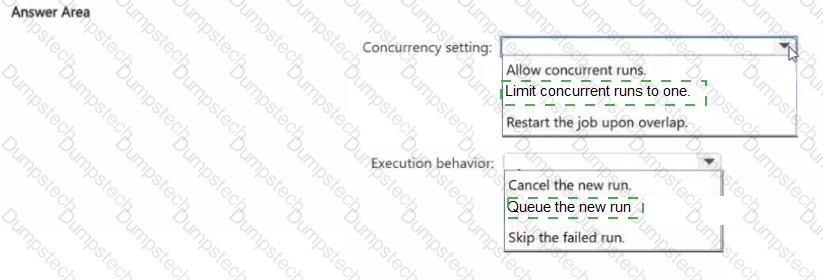
You have an Azure Databricks workspace that contains a job in Lakeflow Jobs named Job1.
Job! runs every hour.
Occasionally, the job run takes longer than one hour to complete. Overlapping runs must be prevented to avoid data corruption.
You need to configure the job scheduling behavior.
What should you configure? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Databricks workspace named Workspace1 that contains a lakehouse and is enabled for Unity Catalog.
You have a connection to a Microsoft SQL Server database named DB1.
You need to expose the schemas and tables of DB1 to meet the following requirements:
• The schemas and tables can be queried in Databricks.
• The schemas and tables appear alongside other Unity Catalog objects.
• The data is NOT copied into Databricks-managed storage.
Solution: You create a Databricks access connector.
Does this meet the goal?
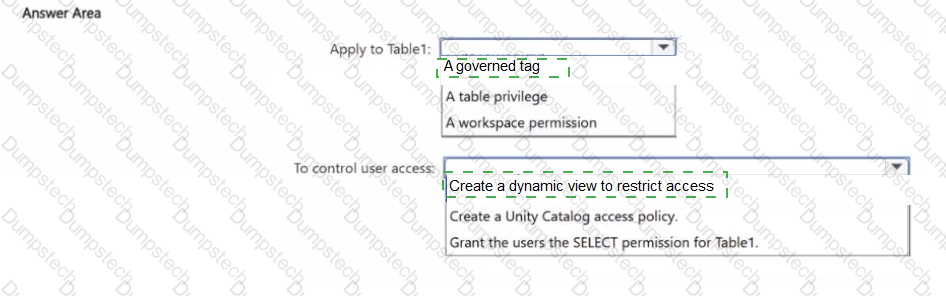
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a catalog named CatalogV Catalog1 contains a schema named Schema! and a table named Table1.
You need to ensure that access to the data in Table1 is controlled by using attribute based access control (ABAC).
What should you apply to Table1, and how should you control access for users? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You need to deploy Databricks Asset Bundles to a development environment. The solution must support automated and repeatable deployments across environments.
What should you use?
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

